며칠 전, WebUI에서도 text-to-video (t2v) 모델을 사용해볼 수 있다는 글을 읽어 보았습니다. 하지만 아직 우분투 클라우드 서버의 WebUI를 통해서 text-to-video 모델을 사용하는 방법에 대한 글을 찾아보기 힘들어서, 직접 사용법에 대한 글을 올리게 되었습니다.
우분투 (Ubuntu) 클라우드 서버에서 WebUI로 Stable Diffusion 기반 Text-to-Image 모델 사용 방법
OpenAI의 DALL-E 시리즈가 2021년부터 나오기 시작한 게 엊그제인 것 같았는데, 지금은 누구나 손쉽게 Text-to-Image 모델을 활용해서 그림을 그리는 세상이 되었네요. 특히, 다양한 stable diffusion 모델을
dino-thinking.tistory.com
아직 우분투 클라우드 서버에 stable diffusion webui가 설치되지 않은 분들은 위에 링크된 글을 참조해서 webui 설치를 먼저 진행하신 이후, 본문을 읽어 보시기 바랍니다.
우분투 클라우드 서버에서 WebUI로 Text-to-Video 모델 사용 방법
우분투 클라우드 서버에 WebUI 설치를 완료하셨다면, WebUI를 실행해서 모델 업로드를 진행합니다. 모델 업로드가 완료되면 아래와 같은 메세지가 출력됩니다.
Running on local URL: [실행시킨 서버의 hostname]:[port]
이제 웹 브라우저를 통해서 WebUI에 접속합니다. 설치는 각 단계마다 순차적으로 진행 해보겠습니다.
단계 1: WebUI의 extension으로 text2video 관련 코드 설치
처음 접속하시면 아래 [사진 1]과 같은 화면이 보이실텐데요, 여기서 붉은색 박스로 표시한 “Extensions”를 클릭합니다.

아래 [사진 2]와 같은 화면이 보이신다면, 붉은색 박스로 표시한 “Available”을 클릭합니다.
여기서 아래 [사진 3]과 같이, 붉은색 박스로 표시한 “Load from” 버튼을 클릭합니다.
다양한 Extension을 확인할 수 있는데요, 우리가 설치해야 할 Extension은 “ModelScope text2video”입니다. WebUI에 도입된지 일주일도 채 안되었네요. 아래 [사진 4]의 붉은색 박스로 표시한 “Install” 버튼을 클릭합니다.
우분투 클라우드 서버에 ssh로 접속한 상태라면, 버튼을 클릭했을 때, 아래와 같은 메세지가 출력됩니다.
Installing ModelScope-text2video requirement: imageio_ffmpeg
그리고 방금 전 [사진 4]에서 “ModelScope text2video” 항목이 없어진 것을 확인할 수 있습니다. 설치가 되었는지 확인하기 위해, 아래 [사진 5]에서 “Apply and restart UI”를 클릭합니다.
이후, 다시 Extensions 탭을 눌러보면, 아래 [사진 6]과 같이, sd-webui-modelscope-text2video가 생성된 것을 확인할 수 있습니다.
다음 단계에서는 우분투 클라우드 서버에 github으로 설치한 stable-diffusion-webui 디렉토리로 이동해서 진행해보겠습니다.
단계 2: 우분투 클라우드 서버에 text-to-video 모델 다운로드 받기
Extensions로 text-to-video 모듈은 설치했지만, 비디오 생성을 위한 모델 파일은 없는 상황입니다. 따라서, 우분투 클라우드 서버 안에 github으로 설치한 stable-diffusion-webui 디렉토리에 모델 파일을 다운로드 받아야 합니다. 우선 [사진 6]에서 붉은색 박스로 표시한 부분의 오른쪽에 https로 시작하는 github URL을 클릭합니다. 이후, 화면을 밑으로 내리다 보면, 아래 [사진 7]과 같은 문구를 발견할 수 있습니다. 여기서 붉은색 박스로 표시된 HuggingFace repository를 클릭합니다.
이제 아래 [사진 8]과 같은 화면을 볼 수 있는데요, 붉은색 박스로 표시한 4개의 파일들을 전부 우분투 클라우드 서버에 다운로드 받아야 합니다. 우선 VQGAN_autoencoder.pth 파일을 예시로 들어서, 설명해보겠습니다. [사진 8]에서 “VQGAN_autoencoder.pth”를 클릭합니다.
아래 [사진 9]와 같은 화면을 보셨다면, 붉은색 박스로 표시한 “download”를 오른쪽 클릭 후, “링크 주소 복사”를 클릭하고 메모장이나 다른 곳에 붙여넣기 해둡니다. 이 URL이 나중에 우분투 클라우드 서버에서 파일을 다운로드 받을 때 사용됩니다.
이제 우분투 클라우드 서버에 접속해서 stable-diffusion-webui 디렉토리 → models 디렉토리로 이동합니다.
cd stable-diffusion-webui/models
여기에 아래 명령어를 입력해서 ModelScope/t2v 디렉토리를 생성합니다. mkdir은 우분투에서 디렉토리를 생성할 때 사용하는 명령어입니다. p 옵션은 생성하려는 디렉토리 내부의 하위 디렉토리까지 한 번에 생성한다는 의미입니다.
mkdir -p ModelScope/t2v
이후, ModelScope 디렉토리 → t2v 디렉토리로 이동합니다.
cd ModelScope/t2v
여기에 방금 전 [사진8]에서 붉은색 박스로 표시된 4개의 파일을 전부 다운로드 받습니다. VQGAN_autoencoder.pth 파일을 예시로, 아래 명령어를 사용해서 다운로드 받습니다. 이 방법으로 open_clip_pytorch_model.bin 파일, text2video_pytorch_model.pth 파일에 대해서, [사진9]에서 “download”를 오른쪽 클릭 후 URL 복사 → wget으로 다운로드 받으면 됩니다.
wget https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis/resolve/main/VQGAN_autoencoder.pth
configuration.json 파일의 경우, 아래 [사진 10]과 같이 “download” 버튼이 보이지 않습니다. 이 때는 “raw” 버튼을 오른쪽 클릭해서 “링크 주소 복사” 후, wget으로 다운로드 받으면 됩니다.
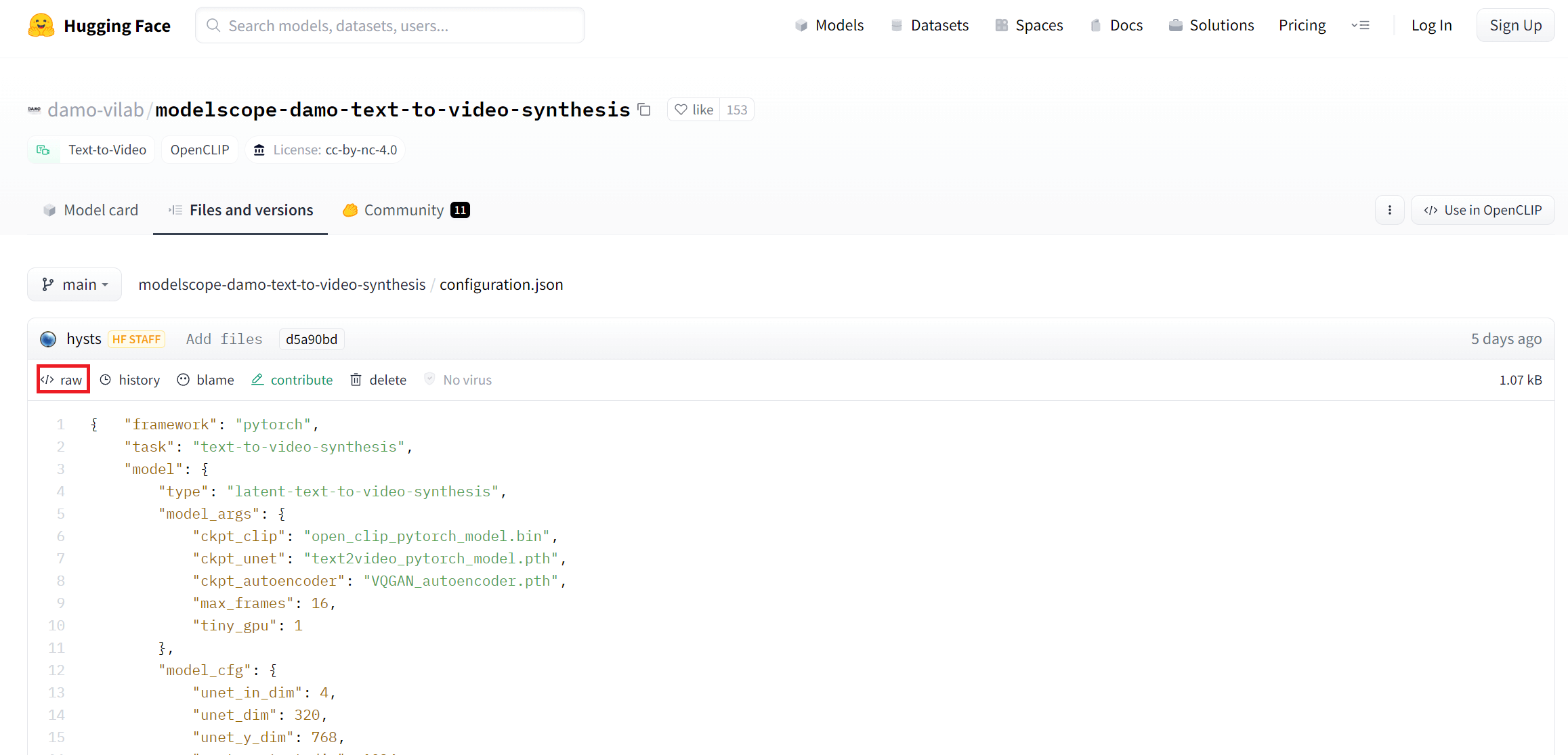
4개의 파일을 모두 다운로드 받았다면, t2v 디렉토리에서 ls 를 입력했을 때, 아래의 4개의 파일이 보이게 됩니다.
ls
VQGAN_autoencoder.pth configuration.json open_clip_pytorch_model.bin text2video_pytorch_model.pth
이제 앞서서 실행시켰던 WebUI를 종료 후, 다시 실행해서 비디오를 생성해보겠습니다.
단계 3: WebUI에서 ModelScope text2video로 비디오 생성
WebUI에 접속하면 아래 [사진 11]과 같이, “ModelScope text2video” 탭이 생성된 것을 확인할 수 있습니다. “ModelScope text2video” 탭을 클릭합니다.
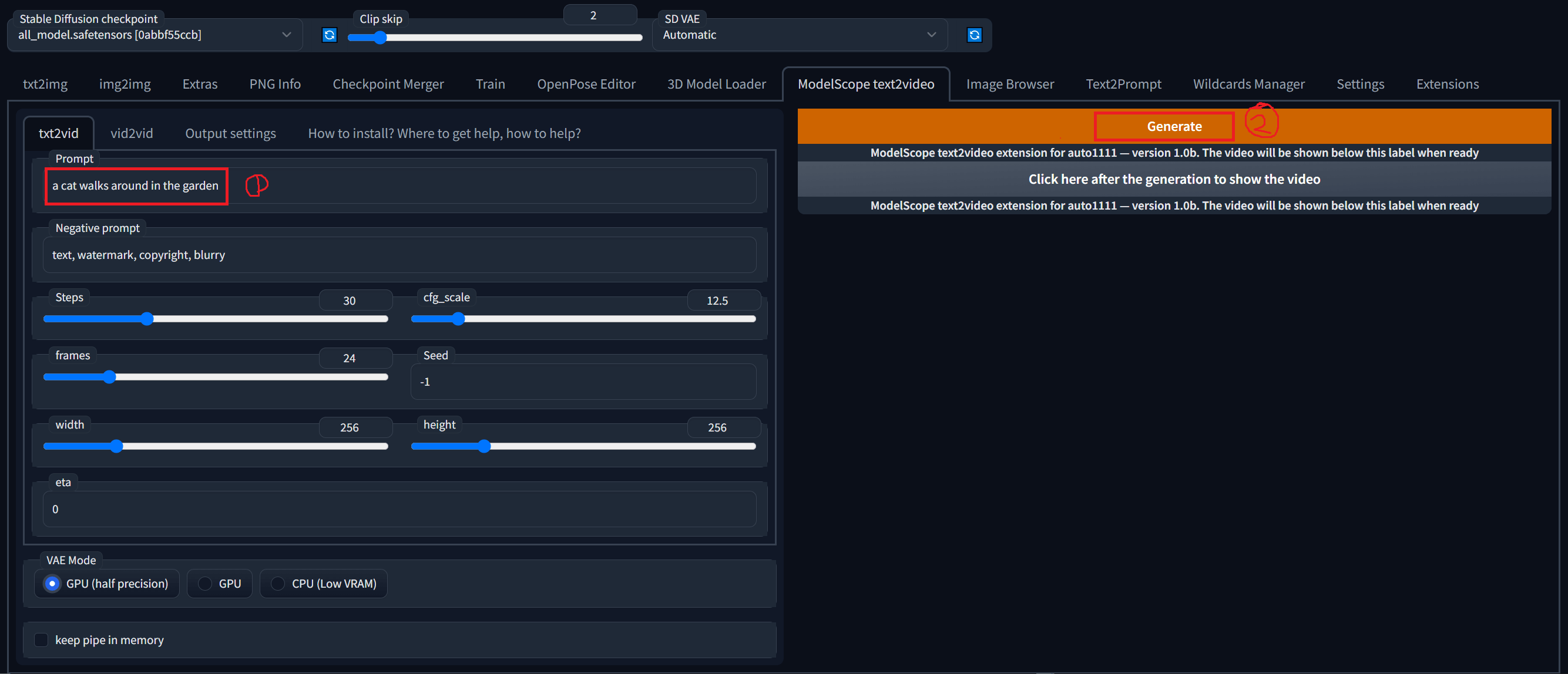
이제 아래 [사진 12]의 화면에서 첫번째 붉은색 박스에 생성하고 싶은 비디오에 대한 prompt를 입력합니다. 이후, 두번째 붉은색 박스로 표시된 “Generate”를 클릭합니다. 우선 모든 옵션은 디폴트로 설정해두었습니다. 물론 다른 옵션을 선택해서 진행해도 좋습니다.
“Generate”를 클릭 후, 우분투 클라우드 서버에서 출력되는 메세지는 아래와 같습니다.
ModelScope text2video extension for auto1111 webui
Git commit: aa53579f (06:37:26 2023)
Starting text2video
Pipeline setup
config namespace(framework='pytorch', task='text-to-video-synthesis', model={'type': 'latent-text-to-video-synthesis', 'model_args': {'ckpt_clip': 'open_clip_pytorch_model.bin', 'ckpt_unet': 'text2video_pytorch_model.pth', 'ckpt_autoencoder': 'VQGAN_autoencoder.pth', 'max_frames': 16, 'tiny_gpu': 1}, 'model_cfg': {'unet_in_dim': 4, 'unet_dim': 320, 'unet_y_dim': 768, 'unet_context_dim': 1024, 'unet_out_dim': 4, 'unet_dim_mult': [1, 2, 4, 4], 'unet_num_heads': 8, 'unet_head_dim': 64, 'unet_res_blocks': 2, 'unet_attn_scales': [1, 0.5, 0.25], 'unet_dropout': 0.1, 'temporal_attention': 'True', 'num_timesteps': 1000, 'mean_type': 'eps', 'var_type': 'fixed_small', 'loss_type': 'mse'}}, pipeline={'type': 'latent-text-to-video-synthesis'})
device cuda
Working in txt2vid mode
latents torch.Size([1, 4, 24, 32, 32]) tensor(-0.0042, device='cuda:0') tensor(1.0032, device='cuda:0')
huh tensor(34) tensor([34], device='cuda:0')
adding noise tensor(34) tensor(0.9838, dtype=torch.float64) tensor(0.1792, dtype=torch.float64)
DDIM sampling tensor(1): 100%|__________________________________________________________________| 1/1 [00:03<00:00, 3.89s/it]
STARTING VAE ON GPU. 24 CHUNKS TO PROCESS
VAE HALVED
DECODING FRAMES
VAE FINISHED
torch.Size([24, 3, 256, 256])
output/mp4s/20230324_081907736303.mp4
text2video finished, saving frames to stable-diffusion-webui/outputs/img2img-images/text2video-modelscope/20230324081754
Got a request to stitch frames to video using FFmpeg.
Frames:
stable-diffusion-webui/outputs/img2img-images/text2video-modelscope/20230324081754/%06d.png
To Video:
stable-diffusion-webui/outputs/img2img-images/text2video-modelscope/20230324081754/vid.mp4
Stitching *video*...
Stitching *video*...
Video stitching done in 0.31 seconds!
t2v complete, result saved at stable-diffusion-webui/outputs/img2img-images/text2video-modelscope/20230324081754
생성된 비디오를 WebUI에서 보려면, 위 [사진 12]의 “Generate” 버튼 밑의 “Click here after the generation to show the video” 버튼을 클릭하면 됩니다.
우분투 클라우드 서버에서 WebUI로 Text-to-Video 모델 사용 방법 요약
지금까지 설명한 우분투 클라우드 서버에서 WebUI로 Text-to-Video 모델 사용 방법은 아래의 세 단계로 요약할 수 있습니다.
- 단계 1: WebUI의 extension으로 text2video 관련 코드 설치
- 단계 2: 우분투 클라우드 서버에 text-to-video 모델 다운로드 받기
- 단계 3: WebUI에서 ModelScope text2video로 비디오 생성
아직 WebUI에 Text-to-video가 적용된 기간이 짧기 때문에, 설치 과정에서 변동 사항이 있다면 업데이트 해두겠습니다.
'IT' 카테고리의 다른 글
| 파이썬 텔레그램 봇 (python-telegram-bot) v20 이상에서 텍스트, 이미지, HTML 파일 전송하는 코드 (0) | 2023.03.09 |
|---|---|
| 아마존 Lightsail 인스턴스에서 매직스플릿만 사용했을 때의 첫 결제 금액 확인 (0) | 2023.03.02 |
| 우분투 (Ubuntu) 클라우드 서버에서 WebUI로 Stable Diffusion 기반 Text-to-Image 모델 사용 방법 (0) | 2023.03.01 |
| 구글 드라이브에 Academic Torrents의 토렌트 파일 다운로드 받는 방법 feat. 구글 코랩 (Colab) (0) | 2022.12.31 |
| 키움증권에 USB에 저장된 타기관 공인인증서 PC에서 등록하는 방법 (0) | 2022.12.30 |


댓글